Машинное обучение в информационной безопасности
Артур Самуэль, один из первых исследователей искусственного интеллекта, описывал машинное обучение как набор методов и технологий, благодаря которым «компьютеры приобретают способность обучаться, не будучи явно запрограммированы».
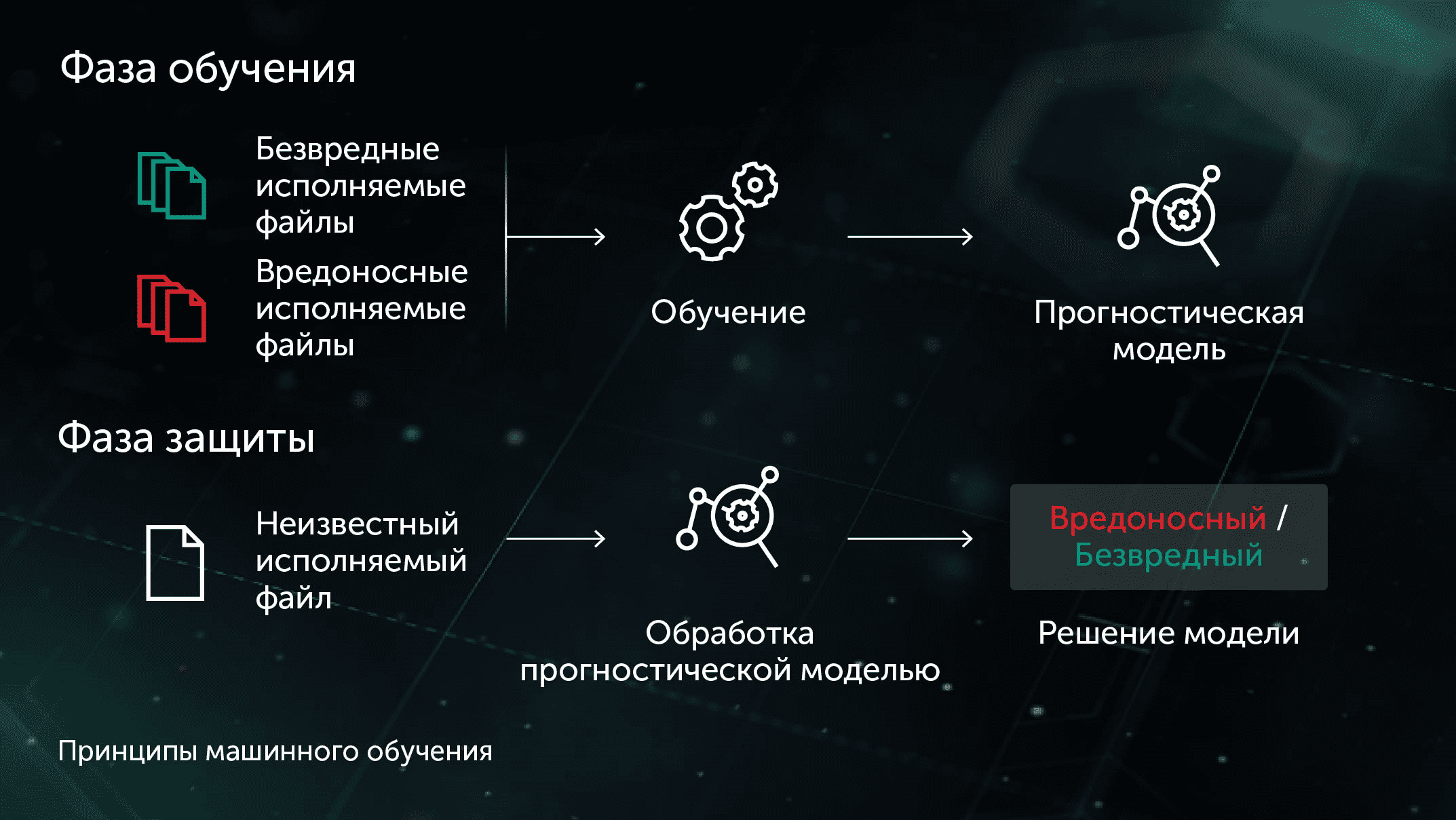
В случае применения методов обучения с учителем в системах защиты от вредоносного ПО задачу можно сформулировать следующим образом. При наличии набора свойств объекта X и соответствующих меток объекта Y в качестве входных данных — необходимо создать модель, которая будет давать корректные определения Y' для ранее неизвестных тестовых объектов X'. За X можно принять некоторые свойства содержимого или поведения файла (статистические данные файла, список используемых функций API и т. п.), а в качестве определений Y использовать просто «безвредный» и «вредоносный» (в более сложных случаях может понадобиться более подробная классификация, включающая такие категории, как вирус, троянец-загрузчик, рекламная программа и т. д.). В случае применения методов обучения без учителя нас больше интересует выявление скрытых структур данных, то есть обнаружение групп схожих объектов или взаимосвязанных свойств.
Многоуровневая защита нового поколения «Лаборатории Касперского» активно применяет методы машинного обучения на всех стадиях процесса обнаружения угроз: от масштабируемых методов кластеризации, используемых для предварительной обработки потока входящих файлов в инфраструктуре, до надежных и компактных моделей для поведенческого анализа, которые создаются на основе глубоких нейронных сетей и работают непосредственно на пользовательских устройствах. Эти технологии разрабатываются с учетом серьезных требований, предъявляемых к методам машинного обучения для обеспечения информационной безопасности в реальном мире. К таким требованиям относятся: чрезвычайно низкий процент ложных срабатываний, интерпретируемость модели и устойчивость к действиям потенциального противника.
Рассмотрим некоторые важнейшие технологии на основе машинного обучения, используемые в продуктах «Лаборатории Касперского» для защиты рабочих станций.
1.1. Ансамбль деревьев решений
При таком подходе прогностическая модель представлена комбинацией деревьев решений (например, методом случайного леса или методом градиентного бустинга). Каждый внутренний узел дерева содержит вопрос, касающийся свойств файла, а листовые узлы содержат окончательное решение дерева относительно объекта. В тестовой фазе модель проходит по дереву решений, отвечая на все вопросы внутренних узлов в соответствии со свойствами рассматриваемого объекта. На финальной стадии все решения, полученные множеством деревьев, усредняются в соответствии с используемым алгоритмом, и выносится конечное решение касательно объекта.
Данная модель позволяет строить эффективную превентивную защиту, выявляя вредоносные файлы до их запуска на рабочей станции.
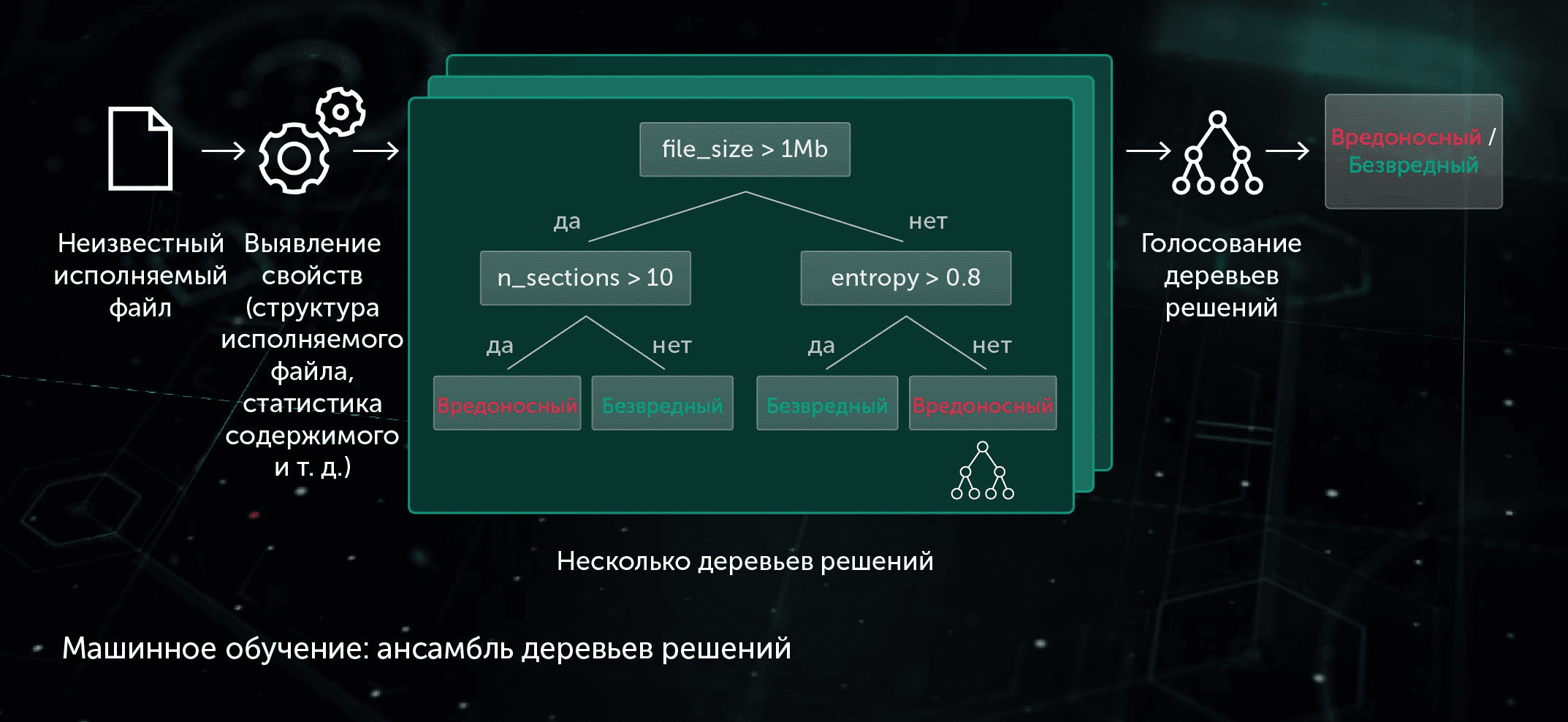
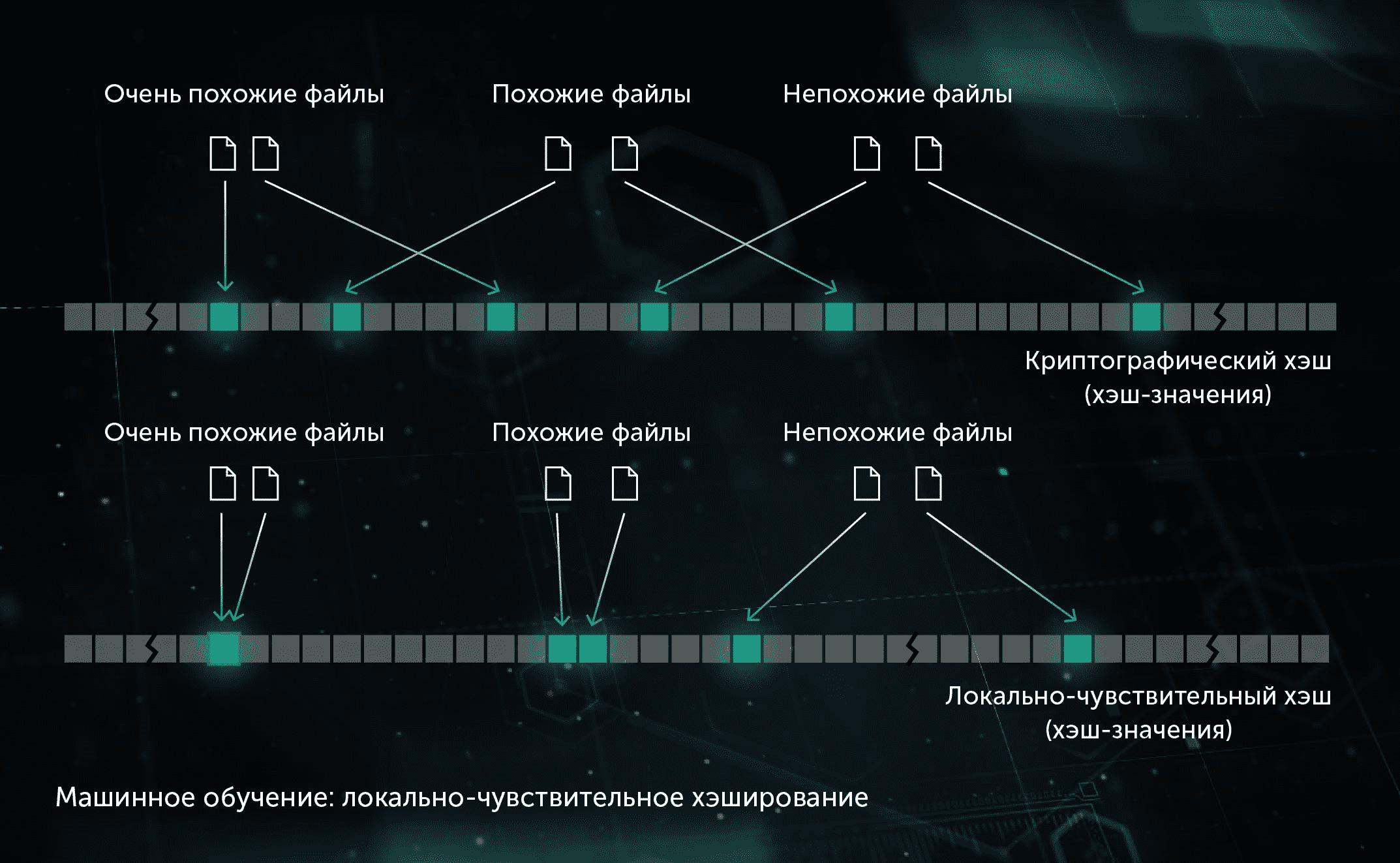
1.2. Локально-устойчивая свертка
При данном подходе мы извлекаем свойства файла и используем метод машинного обучения на основе ортогональных проекций, чтобы выбрать наиболее важные из этих свойств. Этот метод позволяет делать эффективные обобщения: векторы признаков со схожими величинами трансформируются в схожие или идентичные паттерны. Данная модель также работает на стадии превентивной защиты, выявляя вредоносные файлы до их запуска на рабочей станции.
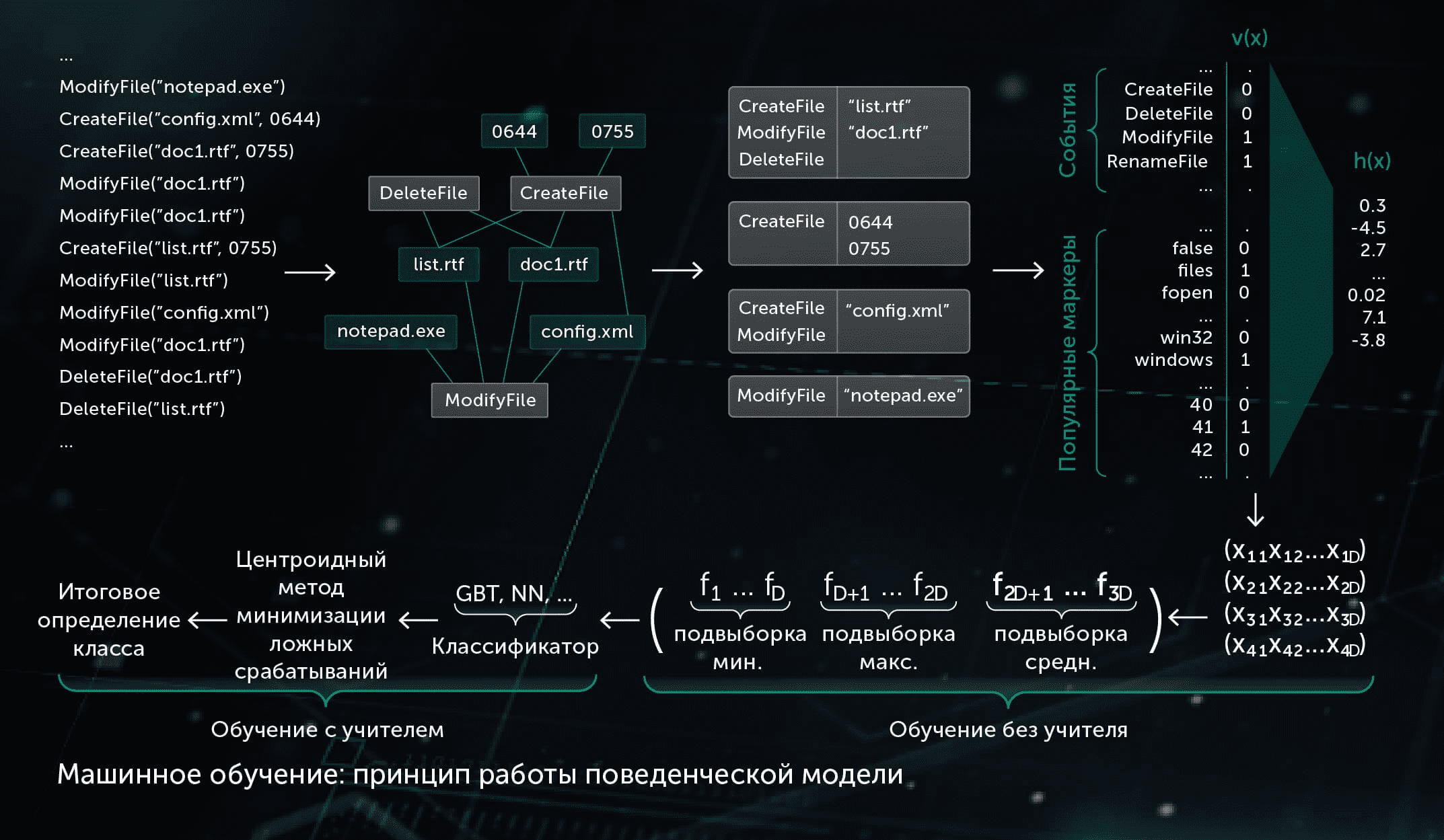
1.3. Поведенческая модель
Компонент анализа поведения составляет журнал поведения, в который записывается последовательность системных событий, произошедших в период выполнения процесса, вместе с соответствующими параметрами. Для обнаружения вредоносной активности по данным журнала наша модель сводит полученную последовательность событий к набору бинарных векторов и обучает глубокую нейронную сеть отличать логи опасной активности от логов легитимных событий.
Данная модель эффективна на этапе проактивной защиты после начала выполнения файла на рабочей станции.
Методы машинного обучения также активно применяются в инфраструктуре «Лаборатории Касперкого» для решения задач кластеризации и классификации.
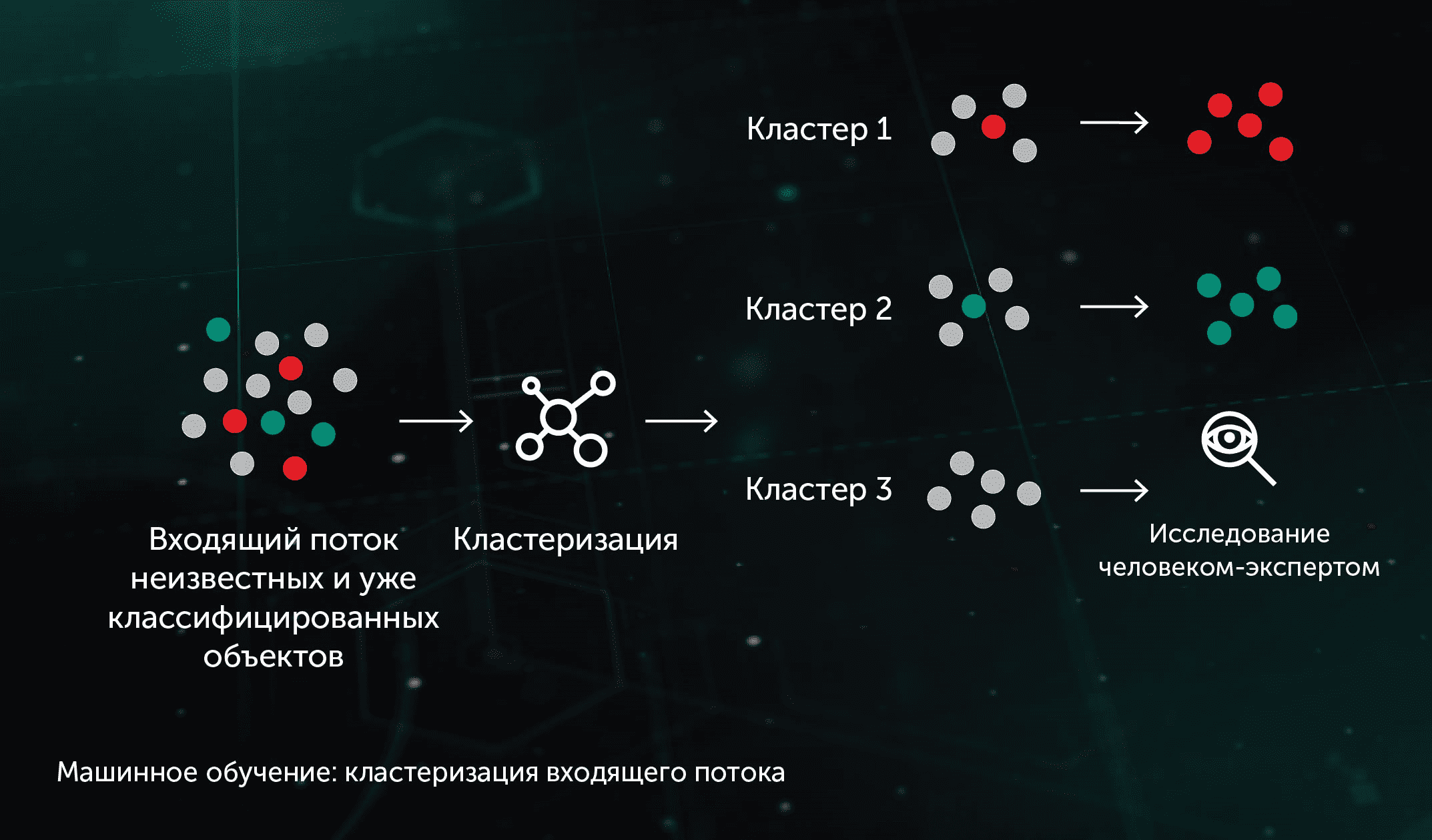
2.1. Кластеризация входящего потока
Алгоритмы кластеризации на основе машинного обучения позволяют эффективно разделять большие объемы поступающих неизвестных файлов на относительно небольшое число кластеров, некоторые из которых могут быть обработаны автоматически благодаря присутствию уже классифицированного объекта в их составе.
2.2. Крупномасштабные модели классификации
Реализация самых эффективных моделей классификации (таких как огромный случайный лес) требует колоссальных ресурсов (процессорного времени, памяти), а также дорогостоящих инструментов анализа (например, для получения подробных журналов поведения может понадобиться применение песочницы). Поэтому такие модели эффективнее строить в лаборатории, а затем применять полученные с их помощью знания для создания более лёгких классификаторов, обучая их на результатах работы большой модели.